Optimizing multilingual SMS
When sending SMS messages in languages that use special characters or longer alphabets, the message length may increase, potentially resulting in message splitting and higher delivery costs. You have several options that will help to optimize your message within the length constraints.
GSM alphabet versus Unicode
The GSM alphabet (GSM-7) is a 7-bit encoding and is the standard encoding for GSM. When using GSM-7, the maximum message length is 160 characters.
If the message includes any character not supported by GSM-7, the message is encoded in Unicode, which reduces the maximum message length to 70 characters. Including a single non-GSM character forces the entire message into Unicode encoding.
If a message exceeds the character limit (160 for GSM, 70 for Unicode), it will be split into multiple parts—each part incurring additional cost.
The GSM character set includes basic characters and extended characters. The following image shows the basic characters on the left and the extended on the right.
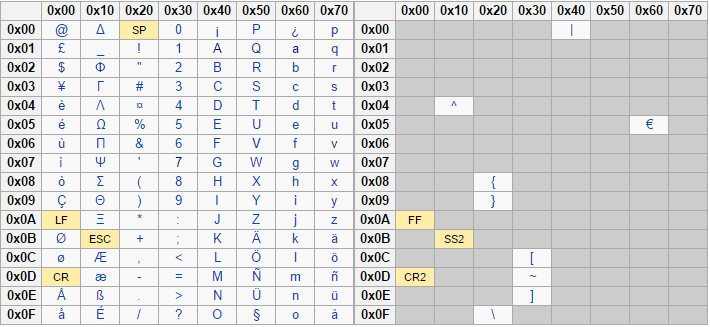
In your SMS, if you have included any characters not supported by GSM alphabet, all characters in the message are encoded in Unicode, and the maximum number of characters reduces to 70 per message.
If the message is longer than 70 characters, it is split into multiple messages. Each subsequent message is limited to 70 characters, even if it contains characters from the GSM alphabet.
To reduce encoding impact and preserve standard message length, use the following options:
- National Language Identifier (NLI)
- SMS transliteration
National Language Identifier
National Language Identifier (NLI) is an encoding technology in the GSM standard that allows SMS messages to identify the language of the content. It indicates that the message contains language-specific characters that must be delivered as the original text, without defaulting to full Unicode.
NLI-encoded messages can contain up to 155 characters (five characters are reserved for metadata).
The five metadata characters are used in the background to inform the receiver’s device about the selected language and instruct it how to properly display the SMS on the device.
To use NLI, include the languageCode parameter in your SMS request. For more information, see Send SMS message (opens in a new tab).
Non-standard characters might cause messages to be encoded in Unicode, which might reduce the number of available characters in the message. Use the SMS preview to explore all options before sending the message.
Supported languages for using NLI in SMS
Supported languages and their codes are:
- Turkish (TR)
- Portuguese (PT)
- Spanish (ES)
- AUTODETECT
Some networks might not support the Language feature. This functionality may not work for all destinations. For example, a message that is Turkish and is sent through a Chinese provider might not be displayed correctly on the recipient’s device.
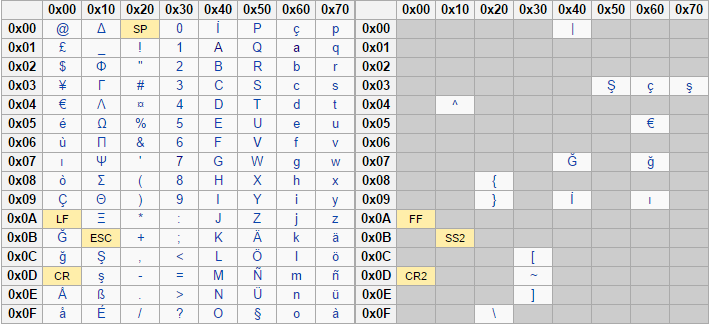
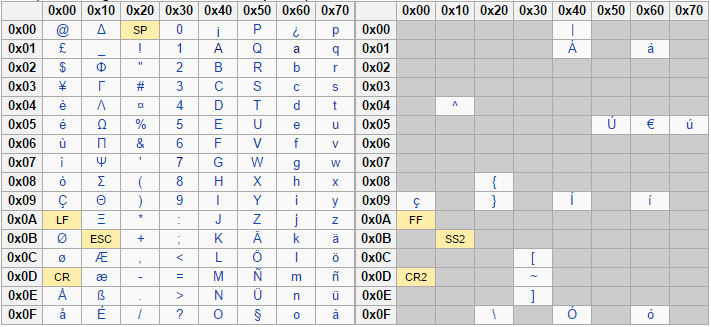
The following images show the list of supported characters for each of the supported languages:
Turkish supported characters for NLI
Portuguese supported characters for NLI
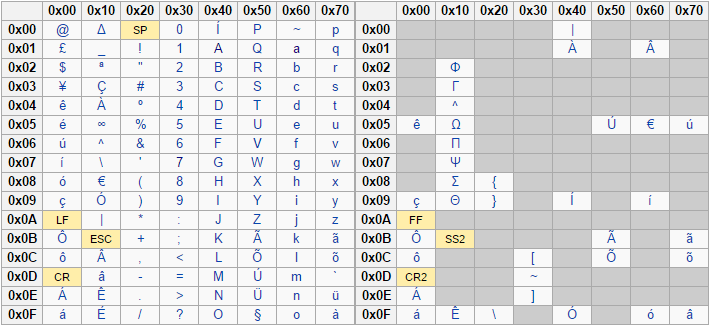
Spanish supported characters for NLI
Example SMS message using Turkish alphabet
The following example shows an SMS message that contains the Turkish alphabet:
{
"messages": [
{
"sender": "InfoSMS",
"destinations": [
{
"to": "41793026727"
}
],
"content": {
"text": "Artık Ulusal Dil Tanımlayıcısı ile Türkçe karakterli smslerinizi rahatlıkla iletebilirsiniz.",
"language": {
"languageCode": "TR"
}
}
}
]
}
For more information, see the SMS language request example in Send SMS message (opens in a new tab).
SMS transliteration
SMS transliteration (opens in a new tab) converts text written in a native script into a Latin-script version of the same message. It replaces any special (unsupported) characters with similar GSM-7-compatible ones.
This process ensures that the maximum of 160 characters can be used in a message instead of only 70 (because of the different encoding standards).
Using SMS transliteration, you can send an SMS messages in your preferred alphabet, which is converted automatically into an appropriately transliterated text. You can use the full capacity of the message text without sending any Unicode characters.
Transliteration can alter the appearance of the message. Use SMS preview to explore all options before sending the message.
Supported languages for using transliteration in SMS
- Turkish
- Greek
- Cyrillic
- Serbian Cyrillic
- Bulgarian Cyrillic
- Central European
- Portuguese
- Colombian
- Baltic
- NON_UNICODE
By specifying the desired output alphabet, some unsupported characters might be converted differently, depending on which character is the most appropriate for the selected language.
Any character that is not recognized by the selected language, and is not part of the GSM alphabet, is replaced by a dot (.).
If you use NON_UNICODE transliteration, the message text is converted from Unicode to GSM alphabet using all available alphabet conversions. For example:
Original text: "©™ø- ˆ¨л- ˙˚λ- ∆ƒ∂"
After NON_UNICODE transliteration: "..ø- ..l- ..A- ..."
Example transliteration message
The following example shows how to send a transliterated message by adding one of the supported alphabets in the transliteration parameter.
{
"messages": [
{
"sender": "InfoSMS",
"destinations": [
{
"to": "41793026727"
}
],
"content": {
"text": "Ως Μεγαρικό ψήφισμα είνα…ι καθολικό εμπάργκο στα",
"transliteration": "GREEK"
}
}
]
}
Text sent: Ως Μεγαρικό ψήφισμα είναι γνωστή η απόφαση της Εκκλησίας του δήμου των Αθηναίων (πιθανόν γύρω στο 433/2 π.Χ.) να επιβάλει αυστηρό και καθολικό εμπάργκο στα
Text received: ΩΣ MEΓAPIKO ΨHΦIΣMA EINAI ΓNΩΣTH H AΠOΦAΣH THΣ EKKΛHΣIAΣ TOY ΔHMOY TΩN AΘHNAIΩN (ΠIΘANON ΓYPΩ ΣTO 433/2 Π.X.) NA EΠIBAΛEI AYΣTHPO KAI KAΘOΛIKO EMΠAPΓKO ΣTA
By using transliteration, Greek lowercase letters that are not supported in the GSM alphabet are converted to uppercase letters that are supported.
The following image shows a list of allowed characters in the GSM alphabet for Greek.
For more information, see the SMS transliteration request example in Send SMS message (opens in a new tab).