Deploying an untested change to production will always cause some amount of stress.
Stress level increases with the importance of a system you are changing. If there is any seasonality in your traffic patterns, stress additionally increases during a “high season“. That may be daily peaks, high traffic periods of the year, the week of your company going public, or any similar seasonality. Every past incident you had when you deployed some change also affects your stress level. The more recent they are, the more stress they add.
In my subjective experience, deploying a tested change reduces stress to almost zero. Even with testing in place, incidents can and will happen, but you have a way to catch them sooner and not repeat them.
Reduced stress is reason enough to put effort into testing changes, even the ones that seem hard or even impossible to test before they reach production.
HAProxy, the testing nemesis
In Infobip, we deploy more than 1000 different changes to production daily. Most of those changes are code, which can be, and is, tested. But there are also changes in network configurations, virtualization, or storage layers, which are much harder to test.
Until recently, one of the things we considered impossible to test was HAProxy configurations. But, as you will read further down the article, we just weren’t thinking enough about it.
All our inbound HTTP traffic passes through an L7 balancing layer where we use HAProxy. Over the years, we have grown to 40+ data centers, many of which have specific configurations. Mostly due to special client requirements, various migrations, and different product stacks available in specific DCs. It’s impossible to have a staging environment addressing all the discrepancies.
Where we fell short before
We tested a change on a single staging environment we had, manipulating the configuration to a similar state to the one we wanted to change in the production. This process was entirely dependent on the engineers making the change.
There was no hard procedure in place that required you to test the change before production. We considered it common sense and preached it, but when someone created a pull request for the change, we never checked if it was tested.
The only requirement for a change to get deployed to production was an approved pull request by one of your fellow engineers. A few incidents later, we increased this to two engineers for the most important systems. We considered this a temporary measure until we thought of something better. Of course, this was a pure “hopium” based strategy.
Here’s an example of one HAProxy-related incident:

This was a change that resulted in serious degradation of our platform. After this was applied, some of the requests on the api.infobip.com endpoint were routed to the wrong backend. As seen in the picture, it was a simple change.
Two engineers approved it, both thinking that HAProxy behaves differently than it does.
One of them was a new hire. Imagine the stress they experienced. And all the flashbacks that occurred when the next change was needed.
We decided to improve this process significantly.
A new approach: Scratch only where it itches
At first, we thought that testing HAProxy configurations before production was inherent to the type of configuration and the way we use it.
“But every HAProxy configuration is unique to aspecific data center!”
“We can’t fake responses of all backends!”
“There is a lot of a client-specific context in our HAProxy configurations, you must understand it to do it right!”
A few costly incidents over the years made us think harder to find a solution. And it wasn’t that hard at all to find it. During the process, we learned that while these statements are still true, they don’t make the configuration untestable.
Our HAProxy configuration consists of many access lists routing traffic to specific backends depending on some regexes. When we took a long hard look at the incidents, we realized around 90% were due to a misconfigured regex or wrong order of access lists.
That’s when we realized we didn’t need to test every line of the HAProxy configuration and make the testing process more complicated than it should be. We should just test the things we are having problems with! Scratch only where it itches!
And this itching part can be tested! If we make it so. So, we did.
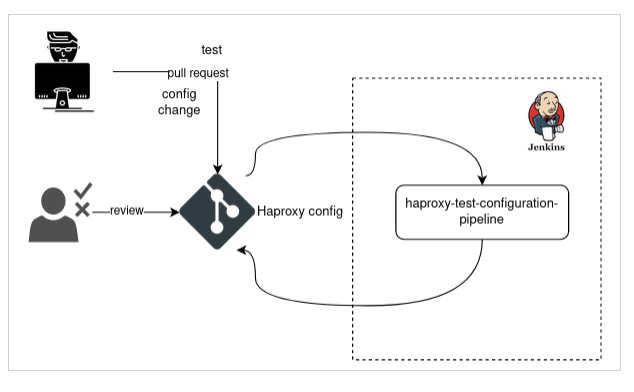
Every change we make in HAProxy configuration now passes a series of tests.
Someone still must approve it, but every change must also pass a series of tests. On some HAProxies, we now run more than 3000 tests on every change. Part of them was auto-generated, and part of them was written manually.
Pipeline stages
Every push to the git repository triggers a Jenkins build, which creates an ad-hoc docker environment, prepares the HAProxy configuration for testing, and runs all the tests.
HAProxy directives that are not subjected to tests are replaced with generic values.
If any test fails, we consider the build failed, and the change cannot be merged to the production branch.
Testing suite
Hurl
We have tried a couple of tools for evaluating responses to HTTP requests, and we chose hurl due to its good assertion engine, simple file format, and test execution speed.
Hurl is a command line tool that runs HTTP requests defined in a simple plain text format.
It can perform requests, capture values, and evaluate queries on headers and body response. It is very versatile: it can be used for both fetching dana and testing HTTP sessions.
It can assert both JSON response and HTTP response headers. Additionally, you can even test whole HTML pages or even Bytes Content.
HTTP-responder
A simple web server that just responds (thus this “brilliant” name) HTTP 200 OK, reflecting everything it received. Every HTTP request header that the HTTP-responder receives is returned in a JSON structure to the client.
During configuration preparation, all backend servers in the HAProxy configuration are pointed to the HTTP-responder. Also, the backend name is injected as a header to every request.
This enables us to check if request is routed to the expected backend.
Or if a reverse proxy injects some required header.
Or if it blocks the request with malicious content in HTTP headers like we configured it.
Tests
Things that we test are:
- access lists and request routing
- HTTP response status codes
- HTTP request header injections
- HTTP response header injections
- HTTP header or URL path rewrites
Writing the tests
To test the behavior of a reverse proxy, you just need to describe the desired result of a specific request.
For example, we have the following directive in our configuration:

To translate, all requests on test.api.infobip.com endpoint with a path beginning with /mobile/ should be routed to the iam-mobile backend.
Now we just write this sentence as a test.
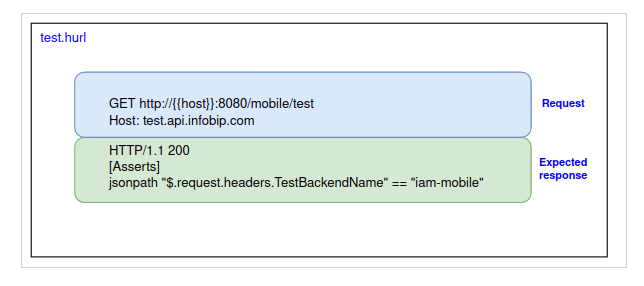
This test is executed on every change. So, if we introduce some faulty regex that would make the traffic on /mobile end up on another backend, this test will fail.
Zero incidents achievement: Unlocked
Introducing a testing pipeline to our configuration change process has improved the quality of our platform, and the number of related incidents dropped to zero. My stress level is also quite close to that number now.
I’d like to encourage you to check your change deployment processes and try to find a spot for automatic testing.
Remember: You don’t have to test everything.
Test what matters.
